


Python libs that I wish were part of the standard library
But I know they can't be
Summary
I'm at this point in my career where whatever new project I start, I usually have an old project I can copy for the baseline.
In the requirement files, I often find again and again some modules that at this point, I wish I didn't have to install anymore and would be provided:
keyring to persist secrets
platformdirs to use conventional paths for storing files
environs to ease environment variables handling
more_itertools because itertools is not enough
pydantic for data validation and serialization
ulid to create lexically dated unique identifiers
chardet and unidecode to deal with bad text encoding citizens
watchdog to react to file changes
peewee as a small ORM
rich to print in the terminal with pretty colors
diskcache for a persistent, fast, embedded key/value store
It's tongue in cheek, I don't actually want them included in the stdlib. But maybe I should make a meta-package :)
This can't be
When you spend a lot of time with a language, you start noticing patterns in what you reach for. Things you always recode. Stuff you always install.
Eventually you start wishing that stuff would be part of the language itself.
For the libs presented in this article, this obviously can't happen. They are too big, they are moving too fast, they may be too specific.
So of course, they are not, and will never be part of the Python stdlib.
But since I like them so much, I suppose you may want to know about them as well.
Persisting secrets with "keyring"
Keyring is a one of those libraries that you would expect to be complicated to install, configure or use.
But it turns out avoiding saving your user’s password or your service token in clear text is one function call away.
You set the credential for an app:
>>> import keyring
>>> keyring.set_password("app_name", "username", "password")
You get back the credential for an app:
>>> keyring.get_password("app_name", "username")
'password'
Under the hood, keyring will use your OS encrypted vault, which means as a programmer, you have zero work to do for managing security or prompting for unlocking. The system does it for you, and it's seamless for your user.
You now have no excuse to put those secret bytes in clear text in a file.
Choosing the right directory with "platformdirs"
Replacing the deprecated "appsdirs", platformdirs answers the question, "where should I put those files?". Indeed, each OS has its own conventions for where to put configuration files, data files, log files, temporary files, etc.
As a Linux user, I particularly dislike apps that pollute my $HOME dir with yet another doted name.
So be a good fellow and use this wonderful tool to put each thing in its place:
>>> from platformdirs import user_cache_dir
>>> user_cache_dir("app_name", "app_name")
'C:\\Users\\bitecode\\AppData\\Roaming\\app_name\\app_name'
Better environment variables management with "environs"
os.environ already allows reading environment variables so what's the point of having a 3rd party library do something that basic?
Well, the environs lib - Not to be confused with the "environ" lib, without the "s" - provides more than accessing environment variables: it makes it easy to parse them, prefix them with namespace, and even load .env files.
It's basically my first import in any django project.
So put this in your config file:
from environs import Env
env = Env()
env.read_env()
with env.prefixed("BITECODE_"):
host = env("HOST", "localhost") # get a string, with default value "localhost"
port = env.int("PORT", 5000) # get an int, default to 5000
expiration = env.date("EXPIRATION") # get a datetime object
factors = env.list("FACTORS", subcast=int) # get a list of ints
And you can now joyfully set your ".env" file in your project with:
BITECODE_EXPIRATION="2001-01-01"
BITECODE_FACTORS=1,2,3
And Ta-da!
>>> host
'localhost'
>>> port
5000
>>> expiration
datetime.date(2001, 1, 1)
>>> factors
[1, 2, 3]
Of course you can set the environment variables manually too, environs is not picky.
More iteration tools with "more_itertools"
The documentation of the superb Python stlib "itertools" module is infamous for having a recipe section. It includes very useful snippets for partially reading generators, iterating on sliding windows and chunks or keeping unique elements.
This is frustrating to say the least, as the author is acknowledging those are very useful things, yet decide those few lines should be copy/pasted ad vitam.
more-itertools solves that problem by including all of them, and more.
I personally install it solely because I'm too lazy to recode a busy "chunked" function. Sorry, too busy to recode a lazy "chunked" function:
>>> from more_itertools import chunked
>>> chunked(range(10), 3)
<callable_iterator object at 0x7f91519eaf20>
>>> list(chunked(range(10), 3))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
Serious data validation with pydantic
There are tons and tons of validation libraries in Python. Some are simpler than pydantic. Some are faster than pydantic. Some have been here for longer.
Still, sometimes, the right tool for the job is like Python: not the best at one thing, but the second-best solution at most things.
pydantic fits this description gracefully. Is it perfect? No. Can you get frustrated with its ergonomics and performances? Sometimes.
Can you rely on it to do the job now and for the next 10 years while playing well with the ecosystem?
Definitely.
>>> class Person(BaseModel):
... name: str
... age: int
...
>>> Person(name="BiteCode", age=12).json()
'{"name": "BiteCode", "age": 12}'
>>> Person.parse_raw('{"name": "BiteCode"}')
...
ValidationError: 1 validation error for Person
age
field required (type=value_error.missing)
Better unique identifier with ulid
uuid.uuid4 is fantastic, I used to use them for everything. Naming images, db primary keys, generating FS trees... But they are totally random, don't hold information and are not sorted, which is not always what you want. UUID 7 is supposed to fix that one day, but since we are going to install a 3rd party lib, why not just go for ulid, which have similar characteristics but have a shorter representation?
ULID identifiers are 128-bit, so they are somewhat compatible with UUID and will fit in most database UUID fields. Their domain allows generating up to 1.21e+24 unique ULIDs per millisecond, so like UUID, they are quite collision resistant.
But, on top of it, those unique identifiers:
Contain their own date of generation, with a generous 80 bits of randomness on top.
Are lexically sortable, meaning their alphabetical order is also their generation order (minus the random part for those generated at the same ms).
Have a canonical representation of only 26 characters (UUID are 32).
Are encoded in Crockford's base32, so hard to confuse. E.G: "L" is uppercased so cannot be confused with "1".
It's quite magical, really.
Let's steal a bunch of those random numbers from the universe!
The same ULID can be represented in different ways:
>>> from ulid import ULID
>>> ulid = ULID() # Generate a new unique number
>>> str(ulid)
'01H08JW6Z10HNZ36X2WS5RZJ69'
>>> ulid.hex
'0188112e1be1046bf19ba2e64b8fc8c9'
>>> int(ulid)
2035728822632514620207534647253387465
>>> ulid.bytes
b'\x01\x88\x11.\x1b\xe1\x04k\xf1\x9b\xa2\xe6K\x8f\xc8\xc9'
You get metadata baked in:
>>> ulid.timestamp
1683915414.497
>>> ulid.milliseconds
1683915414497
>>> ulid.datetime
datetime.datetime(2023, 5, 12, 18, 16, 54, 497000, tzinfo=datetime.timezone.utc)
It's compatible with UUID:
>>> ulid.to_uuid()
UUID('0188112e-1be1-046b-f19b-a2e64b8fc8c9')
And look at that beautiful sorting:
>>> uids = [ULID(), ULID(), ULID(), ULID()]
>>> sorted(uids, key=str) == sorted(uids, key=lambda x: (x.timestamp, str(x)))
True
Deal with bad text encoding citizens with chardet and unidecode
Python 2, if not being dead, is in zombie state, are so we don't have as many text encoding problems as we used to be. Thanks to Python 3, I can now Python my name in a Python file without seeing it explodes if I forget the proper incantations.
Still, the rest of the world didn't get the memo. A huge part of the IT community speaks only English, a language that can blissfully be constructed out of a few ASCII characters and a pinch of gun powder.
So if you ever have to deal with, say, some kind of American administration process, or God forbid, some British university FTP server, you may have to take a trip to memory lane, back to the Stone Age of computing: the 80'. Where nothing has metadata, and the guy on the phone tells you, "its ANSI", as if it meant anything or that you weren't downloading a database full of Swedish usernames.
Enter chardet to attempt to detect the encoding of the blob you have been tasked to extract some semblance of meaning from; and unicodecode, a dark magic tool that will translate your elaborate prose into something those barbarians can ingest without dying:
>>> import chardet
>>> quote = "やめてください先輩".encode('utf8')
>>> chardet.detect(quote)
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
>>> import unidecode
>>> unidecode.unidecode("やめてください先輩")
'yametekudasaiXian Bei '
And yes, the last output is bullshit, but it's debuggable bullshit. Plus it won't crash their graphemophob servers, and that's gold.
React to file changes with watchdog
My rule of thumb is that, if I Ctrl + Z more than 3 times a command during an hour, I watchdog it.
watchdog is like entr with inotify perfs, cross-platform, plus a programmable API.
In short, it looks if files have changed, and run a command if it happens.
You can use it out of the box using the watchmedo command:
watchmedo shell-command --patterns="*.py;*.txt" --recursive --command='echo "${watch_src_path}"' .
This will recursively print the path of any .py or .txt file that is suddenly modified in the current directory.
Or you can do it in a Python script:
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class PrintPath(FileSystemEventHandler):
def on_created(self, event):
rint(event.src_path)
if __name__ == "__main__":
observer = Observer()
observer.schedule(PrintPath(), path='.', recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
You can automate so many things that way. Coupled with doit, this accounts for half my project management process.
An ORM in your pocket with peewee
There are 3 positions about ORM. Those who say they are horrible, those who say they are great, and those who say "shut up, I'm trying to code!".
Now if you do want to use one, you may not want to a whole Web framework just for the DB layer (Django) or use a bazooka (SQLAlchemy), although I use them when the need arise.
Sometimes, you just want a tiny winy cute ORM that fits in your pocket, like peewee.
import peewee as pw
db = pw.SqliteDatabase("store.db")
class Product(pw.Model):
name = pw.CharField()
price = pw.FloatField()
class Meta:
database = db # This model uses the "people.db" database.
db.connect()
db.create_tables([Product])
Product.create(name="Bread", price=0.8)
Product.create(name="Rice", price=1.2)
Product.create(name="EA DLC", price=999999)
for p in Product.select().where(Product.price > 1):
print(p.name, p.price)
Which prints:
Rice 1.2
EA DLC 999999.0
Rich printing
A lot of praises have been said about rich. Not just because the lib is good at nicely displaying text in the terminal, but also because the author, Will McGugan, is so lovable.
However I confess I install it just for pretty printing nested objects and dataclasses. I'm a simple man.
If I have:
from dataclasses import dataclass
@dataclass
class Product:
name: str
price: float
store = [
Product(name="Bread", price=0.8),
Product(name="Rice", price=1.2),
Product(name="EA games DLC", price=999999),
]
Then what do you think is easier to debug?
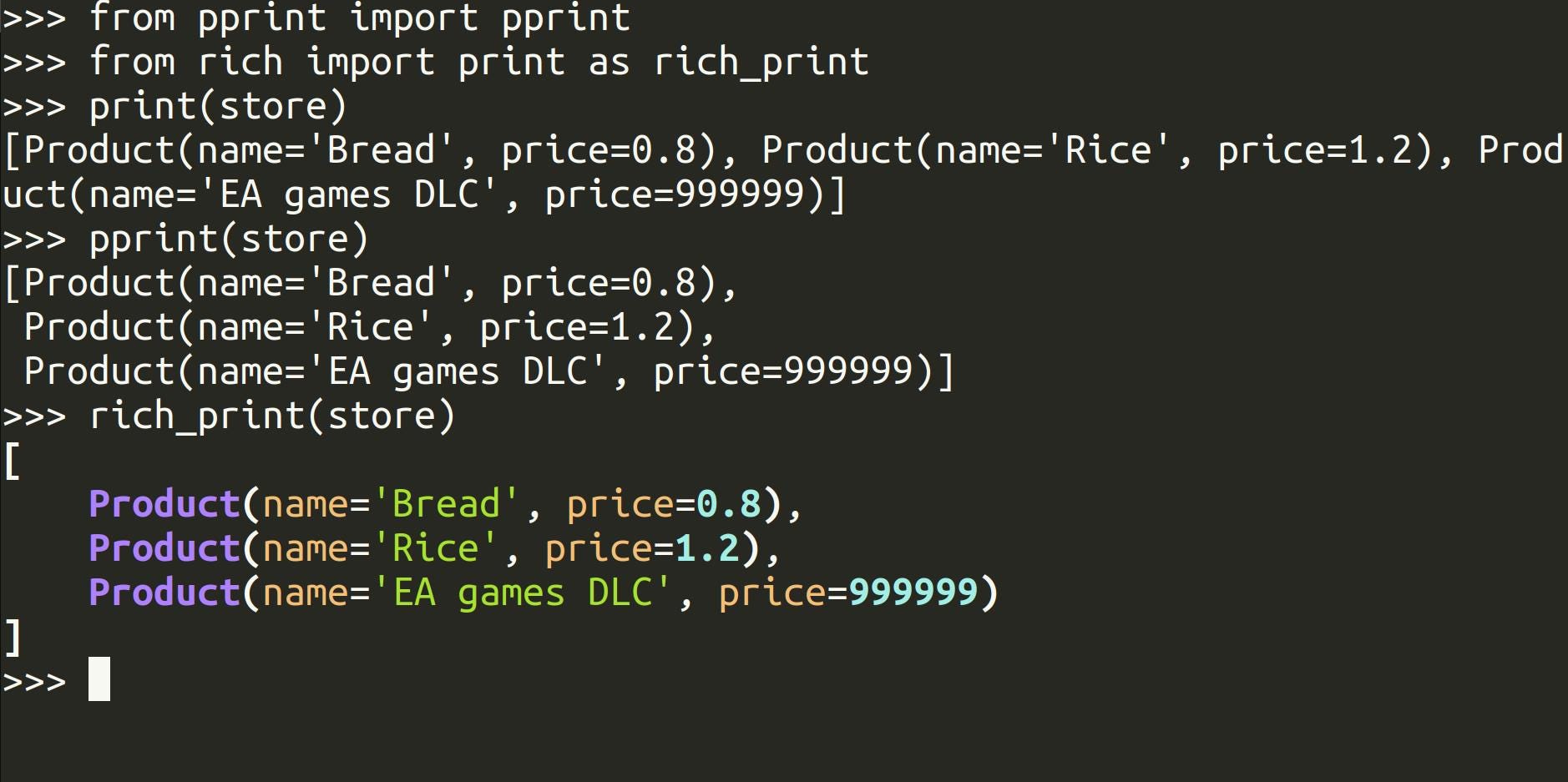
Persistent cache with diskcache
I love Redis. Redis is so reliable, so powerful, so simple. It's so well made I sometimes compile it to remind me it's easy to do, and I let a tear run on my keyboard.
But I don't always have a Redis instance with me.
Still, persisting cache is one of the basic use cases for Redis: it's a fast key/value store, keys can expire, you can access it from several processes...
Trying to do that in pure Python should surely be a complicated task?
Well, if you try to do it with JSON and lock files, or multiprocessing and shelves, yes.
If you use diskcache, no.
Diskcache is a local key/value store, it doesn't need a server, it uses sharded DB files with WAL to allow several processes to read and write to it and pickles things for you. It's grub-smart to use and robust (thanks to our Lord sqlite performing miracles under the hood), so not using it is just criminal.
Write:
>>> from diskcache import Cache
>>>
>>>
>>> with Cache(".") as cache: # use platformdirs for this in prod
... cache['Scrub seasons'] = [1, 2, 3, 4, 5, 6, 7, 8]
Read:
>>> from diskcache import Cache
>>>
>>>
>>> with Cache(".") as cache: # use platformdirs for this in prod
... seasons = cache['Scrub seasons']
... print(seasons)
... print(sum(seasons))
...
[1, 2, 3, 4, 5, 6, 7, 8]
36
Heaven is sometimes just a dict-like away.
I see there are many ulid libraries available. Which one are you using? Thanks in advance.
I’d add the requests library in there too.